
티스토리 뷰
많은 사람들이 주식투자를 하는 목적은 "돈을 벌기 위해서" 일 것입니다.
주식이 적금이나 다른 금융상품보다 수익률이 높기 때문에 목돈을 일부 사용하여 조금씩 주식투자를 시도하는 경향이 강합니다.
하지만 저같은 개인투자자, 즉 개미라고 불리는 사람들은 주식 시장에서 수익을 내기가 쉽지 않습니다.
처음에 우연히 수익을 낼 수 있지만, 무작정 특정 종목이 오를 것 같다고 믿거나 직감에 맡기는 투자 방법은 실패할 확률이 높습니다.
누군가에게 추천받는 종목을 투자하는 방법은 더더욱 위험하죠.
간단하게 정리하면, 개인이 하는 주식 투자는 '정보 및 시간의 부족' 문제를 갖고 있습니다.
알고리즘 트레이딩은 이러한 문제를 조금이나마 극복할 수 있도록 도와줍니다.
● 알고리즘 트레이딩 (Algorithmic Trading)
알고리즘 트레이딩(Algorithmic Trading)이란 어떤 문제를 해결하기 위한 절차나 방법을 의미하는 '알고리즘'과 한국어로 거래를 의미하는 '트레이딩'이 결합된 방법입니다. 즉, 알고리즘 트레이딩이란 ‘컴퓨터를 이용해 어떤 일정한 알고리즘에 따라 자동으로 거래하는 매매 방식’을 의미합니다.
알고리즘 트레이딩의 구체적인 시나리오에 대해 한 번 더 생각 해봅시다. 먼저 컴퓨터가 주식 시장이 개장되기 전에 전날의 거래 패턴(거래량, 종가, 시가, 주식 가격 의 변동 폭)을 분석하고 이를 통해 투자 유망 종목을 자동으로 추천해 줄 수 있습니다. 또는 더 나아가 낮에 일하는 동안 컴퓨터가 자동으로 주식을 매수하고, 매도하면서 수익을 낼 수도 있습니다.
효율적인 프로그램 매매를 위해서는 본인만의 알고리즘, 즉 투자 노하우가 있어야 합니다.
예를 들어, 여러 주식 책을 보면 거래량 분석을 통해 다수의 세력이 장기간에 걸쳐 매집하는 종목을 찾는 알고리즘이 있습니다. 이 알고리즘은 몇 개월 동안 거래량을 분석하고 있다가 특정 종목의 일일 거래량이 최근의 평균 거래량보다 1,000% 이상 급등하는 종목을 찾습니다. 이처럼 단기간의 거래량이 평균 거래량보다 폭발적으로 늘어나는 종목은 단기간에 급등할 수 있다는 것이 주요 아이디어입니다.
문제는 국내 주식 시장(유가증권시장, 코스닥시장)의 주식 종목이 2,000개 정도 되기 때문에 매일 퇴근한 후 이런 종목들을 자세히 조사하고 투자 계획을 세우기가 어렵다는 것입니다.
이 문제의 간단한 해결책은 그런 일들은 컴퓨터가 대신 하게끔 시키면 된다는 것이죠. 사실 컴퓨터는 스스로 생각하거나 판단하는 것은 사람보다 부족할 수 있지만, 다수의 데이터 를 반복적으로 처리하는 것은 사람보다 월등히 잘합니다.
알고리즘이 준비되면 다음 단계는 프로그래밍 언어를 이용해 ‘알고리즘’을 컴퓨터가 알아들을 수 있게 프로그래밍하는 것입니다. 이 책에서는 파이썬으로 설계하는 방법을 설명합니다.
● 파이썬 기초
알고리즘 설계에 필요한 파이썬 기본 지식에 대해 짚고 넘어가겠습니다.
(내용이 많은 관계로 아는 부분은 넘어가셔도 좋을 것 같습니다)
▷ 파이썬 변수와 문자열
- 파이썬으로 하는 계산
파이썬 IDLE에서 계산식을 입력하고 엔터를 누르면 결과가 나옵니다.
>>> (180 * 10) + 10000
11800- 파이썬 변수와 객체
x = 100 이라는 코드를 파이썬 IDLE에서 실행했을 때, 먼저 100이라는 값이 메모리의 어딘가에 할당되는데, 파이썬에서는 이를 객체(object)라고 부릅니다. 변수 x 역시 메모리의 어딘가에 할당되는 공간인데, 그 공간에는 100이라는 객체의 메모리 주솟값이 저장돼 있습니다. 이를 다르게 표현하자면 변수 x는 100이라는 값의 객체를 가리키고 있는 것입니다.
>>> monday_end_price = 10000 - (10000 * 0.3)
>>> tuesday_end_price = monday_end_price - (monday_end_price * 0.3)
>>> tuesday_end_price
4900.0- 파이썬 문자열
위에서 변수를 이용해 메모리에 할당된 어떤 정숫값을 가리키는 것(바인딩)을 배웠는데, 변수로 문자열을 가리킬 수도 있습니다.
>>> mystring = 'hello world'
>>> mystring
'hello world'
'hello world'라고 정상적으로 값이 나오는 것을 확인할 수 있습니다. 이번에는 화면에 값을 출력하는 함수인 print를 통해 mystring이 가리키는 값을 출력해 보겠습니다.
>>> print(mystring)
hello world
문자열의 길이도 확인 가능합니다
>>> mystring = 'hello world'
>>> len(mystring)
11
글자를 불러오는 인덱싱 기능도 가능합니다. 0부터 시작하며, 음수를 사용할 경우 뒤쪽부터 역순으로 글자를 셉니다.
>>> mystring[0:5]
'hello'
>>> mystring[6:11]
'world'
>>> mystring[6:]
'world'
>>> mystring[:5]
'hello'
>>> mystring[6:-1]
'worl'
문자열을 자르는 기능도 있습니다.
>>> my_jusik = "naver daum"
>>> split_jusik = my_jusik.split(' ')
>>> split_jusik
['naver', 'daum']
>>> print(split_jusik[0])
naver
문자열을 합칠 수도 있습니다.
>>> daum = "Daum"
>>> kakao = "KAKAO"
>>> daum_kakao = daum + ' ' + kakao
>>> daum_kakao
'Daum KAKAO'- 기본 데이터 타입
크게 str, int, float가 있습니다.
>>> type('python')
<class 'str'>>>> type(70000)
<class 'int'>
>>> type(3.141592)
<class 'float'>
▷ 파이썬 기본 자료 구조
- 리스트
관심 종목을 파이썬으로 관리해야 한다면, 변수를 이용해 다음과 같이 관심 종목명을 문자열로 표현한 후 가리키게 할 수 있을 것입니다.
>>> interest1 = "삼성전자"
>>> interest2 = "LG전자"
>>> interest3 = "네이버"
하지만 관심종목이 많을 경우 이런 방식이 불편할 수 있는데, 이러한 불편을 해결하고자 파이썬에서는 리스트(list)라는 기본 자료구조를 제공합니다. 리스트 안의 데이터는 리스트의 인덱스 값을 통해 접근할 수 있습니다.
>>> interest = ["삼성전자", "LG전자", "네이버"]
>>> interest[0]
'삼성전자'
>>> interest[1]
'LG전자'
>>> interest[2]
'네이버'
리스트 생성과 인덱싱 예시를 하나 더 들어보겠습니다. 양수와 음수 인덱싱 모두 가능합니다.
>>> daishin = [9130, 9150, 9150, 9300, 9400]
>>> daishin[0]
9130
>>> daishin[4]
9400
>>> daishin[-1]
9400
>>> daishin[-5]
9130
시가 총액 10위 목록(2015. 6. 28 기준)에 대한 데이터 확인 및 리스트 슬라이싱을 해보겠습니다.
>>> kospi_top10 = ['삼성전자', 'SK하이닉스', '현대차', '한국전력', '아모레퍼시픽',
'제일모직', '삼성전자우', '삼성생명', 'NAVER', '현대모비스']
아래와 같이 리스트 인덱스를 이해하고, 데이터 확인 및 리스트 슬라이싱을 한 결과입니다.

# 시가총액 5위 확인
>>> print("시가총액 5위: ", kospi_top10[4])
시가총액 5위: 아모레퍼시픽
# 코스피 상위 5종목 확인
>>> kospi_top5 = kospi_top10[0:5]
>>> kospi_top5
['삼성전자', 'SK하이닉스', '현대차', '한국전력', '아모레퍼시픽']
리스트에 데이터를 삽입하기 위해서는 append, insert 두 가지 메소드를 사용할 수 있습니다.
append 메소드는 데이터를 항상 리스트에 끝에 삽입하고, insert 메소드는 사용자가 원하는 위치에 데이터를 삽입할 수 있습니다. append와 insert 사용 예시를 차례대로 적어보겠습니다.
>>> kospi_top10 = ['삼성전자', 'SK하이닉스', '현대차', '한국전력', '아모레퍼시픽',
'제일모직', '삼성전자우', '삼성생명', 'NAVER', '현대모비스']
>>> kospi_top10.append('SK텔레콤')
>>> kospi_top11 = kospi_top10
>>> kospi_top11
['삼성전자', 'SK하이닉스', '현대차', '한국전력', '아모레퍼시픽',
'제일모직', '삼성전자우', '삼성생명', 'NAVER', '현대모비스', 'SK텔레콤']
예제처럼 코스피 상위 10개 종목이 있는데, 11위였던 'SK텔레콤'이 시가총액 기준으로 4위로 갑자기 상승한 경우를 생각해봅시다. 이 경우 insert(3, 'SK텔레콤')을 통해 4위에 'SK 텔레콤'을 삽입할 수 있습니다.
>>> kospi_top10 = ['삼성전자', 'SK하이닉스', '현대차', '한국전력', '아모레퍼시픽',
'제일모직', '삼성전자우', '삼성생명', 'NAVER', '현대모비스']
>>> kospi_top10.insert(3, 'SK텔레콤')
>>> kospi_top11 = kospi_top10
>>> kospi_top11
['삼성전자', 'SK하이닉스', '현대차', 'SK텔레콤', '한국전력',
'아모레퍼시픽', '제일모직', '삼성전자우', '삼성생명', 'NAVER', '현대모비스']
리스트 데이터 삭제도 간단합니다. 위 데이터에서 내장함수 len을 사용하여 리스트 데이터의 개수를 확인 후 del 함수를 사용하여 시가총액 11위인 '현대모비스'를 삭제해보겠습니다.
>>> len(kospi_top11)
11
>>> kospi_top11[-1]
'현대모비스'
>>> del kospi_top11[-1]
>>> kospi_top10 = kospi_top11
>>> kospi_top10
['삼성전자', 'SK하이닉스', '현대차', 'SK 텔레콤', '한국전력',
'아모레퍼시픽', '제일모직', '삼성전자우', '삼성생명', 'NAVER']
>>> len(kospi_top10)
10- 튜플
튜플(tuple)도 여러 개의 데이터를 순서대로 담아두는 데 사용합니다. 단, 튜플과 리스트는 다음과 같은 두 가지 차이점이 있습니다.
1) 리스트는 '[' 와 ']'를 사용하는 반면 튜플은 '('와 ')'를 사용한다.
2) 리스트는 리스트 내의 원소를 변경할 수 있지만 튜플은 변경할 수 없다.
예시와 함께 살펴보겠습니다. 튜플은 리스트와 비슷하게 인덱싱을 통해 튜플의 원소에 접근할 수 있습니다.
>>> t = ('Samsung', 'LG', 'SK')
>>> t
('Samsung', 'LG', 'SK')
>>> len(t)
3
>>> t[0]
'Samsung'
>>> t[1]
'LG'
>>> t[2]
'SK'먼저 len 내장 함수를 이용해 튜플의 원소의 개수를 확인해 보니 총 3개가 있는 것을 확인했습니다.
다음과 같이 [0], [1], [2] 인덱싱을 통해 튜플의 각 원소에 접근하는 것을 확인할 수 있습니다.
그러나 튜플은 리스트와 달리 원소를 수정할 수 없으므로 원소의 내용을 바꾸려고 하면 에러가 발생합니다
>>> t[0] = "Naver"
Traceback (most recent call last):
File "<pyshell#7>", line 1, in <module>
t[0] = "Naver"
TypeError: 'tuple' object does not support item assignment튜플도 리스트와 동일하게 슬라이싱이 가능합니다. 다음과 같이 t가 바인딩하는 튜플에서 'Samsung'과 'LG'만 가져오려면 다음과 같이 슬라이싱하면 됩니다.
>>> t
('Samsung', 'LG', 'SK')
>>> t[0:2]
('Samsung', 'LG')- 딕셔너리
파이썬에서 리스트, 튜플과 함께 자주 사용되는 자료구조로 딕셔너리(dictionary)가 있습니다. 파이썬의 딕셔너리는 영어사전과 마찬가지로 키(key)와 값(value)이라는 것을 쌍으로 저장함으로써 더 쉽게 저장된 값을 찾을 수 있는 구조입니다.
딕셔너리는 '{'와 '}' 기호를 사용합니다. 리스트와 튜플을 복습해보면 리스트는 '['와 ']' 기호를 사용했고, 튜플은 '('와 ')' 기호를 사용했습니다. 아무것도 들어 있지 않은 빈 딕셔너리를 하나 만들고 type 함수로 확인해 보겠습니다.
>>> cur_price = {}
>>> type(cur_price)
<class 'dict'>
원소가 들어 있지 않은 딕셔너리가 잘 만들어졌으니 딕셔너리에 키-값 쌍을 하나 추가해 보겠습니다. 대신증권의 ‘현재가’가 30,000원이라고 하면 다음과 작성하면 됩니다. 여기서 'daeshin'이 키(key)고 30000이 값(value)이 됩니다. 데이터가 잘 추가되었는지 딕셔너리도 확인해보겠습니다.
>>> cur_price['daeshin'] = 30000
>>> cur_price
{'daeshin': 30000}
이번에는 'Daum KAKAO' 한 주의 현재가가 80,000원이라는 것을 딕셔너리에 추가한 후 cur_price에 값이 잘 입력됐는지도 확인해보겠습니다.
>>> cur_price['Daum KAKAO'] = 80000
>>> cur_price
{'Daum KAKAO': 80000, 'daeshin': 30000}
내장 함수 len을 사용하여 데이터의 개수도 확인 가능합니다. 현재 cur_price 딕셔너리에는 두 개의 키-값 쌍이 입력돼 있으므로 len 내장 함수의 반환값이 2라는 것을 확인할 수 있습니다.
>>> len(cur_price)
2
파이썬의 딕셔너리는 리스트와 튜플과 달리 인덱싱을 지원하지 않습니다. 따라서 다음과 같이 딕셔너리에 정숫값을 이용해 인덱싱하면 오류가 발생하므로, 키 값을 사용하여 데이터를 구해야 합니다.
>>> cur_price[0]
Traceback (most recent call last):
File "<pyshell#18>", line 1, in <module>
cur_price[0]
KeyError: 0
>>> cur_price['daeshin']
30000
데이터 삽입과 삭제를 다시 한번 연습해보겠습니다. 위의 cur_price에 naver의 현재가를 추가합니다.
>>> cur_price['naver'] = 800000
>>> cur_price
{'Daum KAKAO': 80000, 'naver': 800000, 'daeshin': 30000}
참고로 다음과 같이 초기값을 넣어서 딕셔너리를 생성할 수도 있습니다.
>>> cur_price = {'Daum KAKAO': 80000, 'naver':800000, 'daeshin':30000}
>>> cur_price
{'naver': 800000, 'Daum KAKAO': 80000, 'daeshin': 30000}
딕셔너리에 저장된 데이터를 삭제하려면 리스트와 마찬가지로 del을 사용하면 됩니다.
>>> del cur_price['daeshin']
>>> cur_price
{'naver': 800000, 'Daum KAKAO': 80000}
딕셔너리에 있는 키 값만 구하기 위해서는 keys 메소드를 호출하면 됩니다.
>>> cur_price = {'Daum KAKAO': 80000, 'naver':800000, 'daeshin':30000}
>>> cur_price.keys()
dict_keys(['naver', 'Daum KAKAO', 'daeshin'])
keys 메소드의 반환값을 보면 'Daum KAKAO'와 'naver'가 파이썬의 리스트로 표현된 것 같기도 한데 그 앞에 'dict_keys' 라는 것이 있습니다. 사실 keys 메소드의 반환값은 리스트가 아니며, 리스트로 만들려면 list라는 키워드를 이용해 타입을 변환해야 합니다. 결과 확인 후 stock_list라는 이름의 변수로 list의 반환값을 바인딩 하겠습니다.
>>> list(cur_price.keys())
['naver', 'Daum KAKAO', 'daeshin']
>>> stock_list = list(cur_price.keys())
>>> stock_list
['naver', 'Daum KAKAO', 'daeshin']
딕셔너리에서 키 목록을 구하는 것과 비슷하게 값 목록을 구하려면 values라는 메서드를 사용하면 됩니다.
>>> price_list = list(cur_price.values())
>>> price_list
[800000, 80000, 30000]
'Samsung'이라는 종목의 현재가를 cur_price라는 딕셔너리로부터 구해야 한다고 해봅시다. 이를 위해서는 앞서 이야기한 것처럼 먼저 'Samsung'이라는 키 값이 cur_price 딕셔너리에 있는지 확인해야 합니다. 딕셔너리의 키 값은 keys 메서드를 통해 얻을 수 있었죠? 다음과 같이 in 이라는 키워드와 keys 메서드의 반환값을 이용하면 이를 쉽게 조회할 수 있습니다. 'Samsung'과 'naver'의 키 값 여부를 확인하겠습니다.
>>> 'Samsung' in cur_price.keys()
False
>>> 'naver' in cur_price.keys()
True▷ 제어문
- Boolean
Boolean(불리언)도 알게 모르게 자주 사용되는 기본 자료형입니다. 다만 Boolean은 다른 자료형과 달리 True 또는 False라는 값만 바인딩할 수 있습니다. bool은 Boolean의 줄임말입니다.
>>> a = True
>>> type(a)
<class 'bool'>>>> b = False
>>> type(b)
<class 'bool'>
>>>
(표) 파이썬 비교 연산자
| 연산자 | 연산자 의미 |
| == | 같다. |
| != | 다르다. |
| > | 크다. |
| < | 작다. |
| >= | 크거나 같다. |
| <= | 작거나 같다. |
위 비교 연산자를 활용한 예시 코드입니다.
>>> 3 == 3
True
>>> 3 != 3
False
>>> 3 < 3
False
>>> 3 > 3
False
>>> 3 <= 3
True
>>> 3 >= 3
True
>>> mystock = "Naver"
>>> mystock == "Naver"
True
>>> day1 = 10000
>>> day2 = 13000
>>> (day2- day1) == (day1 * 0.3)
True- 논리 연산자
앞서 비교 연산자를 이용해 상한가를 확인하는 코드를 작성해봤습니다. 그러나 사실 한국 거래소(www.krx.co.kr)의 가격제한폭 제도를 살펴보면 정확한 상한가를 산출하는 방식은 기준 가격(전일 종가)에 단순히 0.3을 곱하는 것이 아니며 다음과 같이 조금 복잡하게 계산됩니다.
1차 계산: 기준 가격에 0.3을 곱한다.
2차 계산: 기준 가격의 호가 가격단위에 미만을 절사한다.
3차 계산: 기준 가격에 2차 계산에 의한 수치를 가감하되, 해당 가격의 호가 가격단위 미만을 절사한다.
#예를 들어, 기준 가격이 9,980원인 경우
1차 계산: 9,980원 x 0.3 = 2,994원
2차 계산: 2,990원(기준 가격(9,980원)의 호가 가격단위인 10원 미만 절사)
3차 계산:
합산가격: 9,980원 + 2,990원 = 12,970원
호가 가격단위 적용: 12,970원의 호가 가격단위인 50원 미만 절사(2차 절사)
상한가: 12,950원
(표) 호가 가격 단위
| 구분 | 단위 |
| 1,000원 미만 | 1원 |
| 1,000원 이상 5,000원 미만 | 5원 |
| 5,000원 이상 10,000원 미만 | 10원 |
| 10,000원 이상 50,000원 미만 | 50원 |
| 50,000원 이상 100,000원 미만 | 100원 |
| 100,000원 이상 500,000원 미만 | 500원 |
| 500,000원 이상 | 1,000원 |
다음 코드는 cur_price가 바인딩하고 있는 기준 가격이 ‘5,000원 이상 10,000원 미만’의 호가 구간에 해당하는지 나타냅니다.
>>> cur_price = 9980
>>> cur_price >= 5000 and cur_price < 10000
True
다음 코드와 같이 or라는 논리 연산자를 사용해 대략 상한가와 비슷하게 오른 종목을 찾을 수도 있습니다. 다음 코드는 당일 종가(day2)에서 전일 종가(day1)를 뺀 금액이 전일 종가의 30%에 해당하는 금액이거나 29.2%에 해당하는 금액보다 큰 금액이면 상한가로 판단합니다. or 연산자는 나열된 여러 가지 조건 중 하나라도 True이면 연산의 결과로 True를 반환합니다.
>>> day1 = 10000
>>> day2 = 13000
>>> ((day2- day1) == (day1 * 0.3)) or ((day2-day1) > (day1 * 0.292))
True- if 문
if ~ else 문을 사용하여 10000원 이상일 때 Buy 10을 출력, 아닐 경우 Holding을 출력하겠습니다. 동일한 방법을 이용하여 향후 시스템을 구현할 때 특정 가격 이상인 경우 판매할 수 있도록 코딩할 수 있습니다.
>>> wikibooks_cur_price = 9000
>>> if wikibooks_cur_price >= 10000:
print("Buy 10")
else:
print("Holding")
Holding
if ~ elif ~ else문을 사용하여 호가 가격 단위를 구해보겠습니다
>>> price = 7000
>>> if price < 1000:
bid = 1
elif price >= 1000 and price < 5000:
bid = 5
elif price >= 5000 and price < 10000:
bid = 10
elif price >= 10000 and price < 50000:
bid = 50
elif price >= 50000 and price < 100000:
bid = 100
elif price >= 100000 and price < 500000:
bid = 500
elif price >= 500000:
bid = 1000
>>> bid
10- for 문
for 반복문과 range를 같이 사용하면 간단하게 정수 범위를 표현할 수 있습니다. range(1, 10)을 list라는 키워드를 통해 리스트 객체로 변환해보면 리스트에 정말로 1부터 9까지 저장되어 있습니다.
>>> list(range(1,10))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
for 문을 사용한다면 차례대로 출력할 수 있습니다.
>>> for i in range(0, 10):
print(i)
for와 리스트를 함께 사용하면 아래와 같이 항목별로 출력할 수 있습니다.
>>> interest_stocks = ["Naver", "Samsung", "SK Hynix"]
>>> for company in interest_stocks:
print("%s: Buy 10" % company)
Naver: Buy 10
Samsung: Buy 10
SK Hynix: Buy 10
for와 딕셔너리를 사용한다면 다음과 같은 코드를 작성할 수 있습니다.
>>> interest_stocks = {"Naver":10, "Samsung":5, "SK Hynix":30}
>>> for company in interest_stocks.keys():
print("%s: Buy %s" % (company, interest_stocks[company]))
SK Hynix: Buy 30
Naver: Buy 10
Samsung: Buy 5- while 문
while 문을 이용해 다섯 번의 상한가 후의 가격을 계산할 수 있습니다
>>> wikibooks = 10000
>>> day = 1
>>> while day < 6:
wikibooks = wikibooks + wikibooks * 0.3
day = day + 1
>>> wikibooks
37129.3
while과 if를 사용해 1부터 10까지 숫자 중 홀수(나머지가 1)인 값을 출력하는 코드입니다.
>>> num = 0
>>> while num <= 10:
if num % 2 == 1:
print(num)
num += 1
반복문에서 break를 사용하면 반복문 전체를 빠져나오게 됩니다. while과 break를 사용해 0부터 10까지의 숫자를 출력하는 코드입니다.
>>> num = 0
>>> while 1:
print(num)
if num == 10:
break
num += 1
파이썬 프로그램이 실행되다가 continue를 만나면 그 아래의 코드를 수행하지 않고 while 문의 조건을 판단하는 곳으로 점프하게 됩니다. 아래 코드를 실행하면 5를 제외하고 1부터 10까지 출력됩니다.
>>> num = 0
>>> while num < 10:
num += 1
if num == 5:
continue
print(num)- 중첩 루프
반복문이 여러 개 겹쳐 있는 구조를 중첩 루프라고 합니다. 예시는 구구단 작성 코드입니다.
(참고: end=' '를 사용하면 줄바꿈없이 출력 가능합니다)
for i in range(1,10):
for j in range(1,10):
print("%s * %s = %s" % (i, j, i*j),end='')
print()▷ 파이썬 함수와 모듈
중복 코드를 재사용하고 싶을 때는 단순히 코드를 복사해서 붙여넣는 식으로 프로그램을 작성하는 것이 아니라 함수(function)라는 형태로 코드를 작성하는 것이 좋습니다.
파이썬에서 화면에 값을 출력할 때 사용했던 print라는 함수는 여러분이 직접 구현하지 않았음에도 이것을 호출해서 사용했던 것을 생각해보면 함수가 얼마나 유용한지 알 수 있습니다. 리스트나 튜플에 들어있는 원소의 개수를 확인할 때 사용하는 내장 함수 len도 기억나실 겁니다. 파이썬에서 제공되는 기본 함수를 살펴보고 유용한 기능을 수행하는 함수도 만들어 보겠습니다.
아울러 파이썬의 모듈에 대해서도 알아보겠습니다. 파이썬의 모듈(module)은 함수보다 더 큰 단위의 코드 묶음을 의미합니다. 보통 함수가 수십 줄 내의 코드로 구성된다면 모듈은 파일 단위의 코드 묶음을 의미합니다.
- 함수
입력 값인 n만큼 문자열이 출력되는 함수입니다.
>>> def print_ntimes(n):
for i in range(n):
print("대신증권")
>>> print_ntimes(1)
대신증권
>>> print_ntimes(2)
대신증권
대신증권
>>> print_ntimes(3)
대신증권
대신증권
대신증권- 반환값이 있는 함수
상한가를 구하는 함수입니다. 함수에서 계산된 값은 return을 통해 항상 반환해야(돌려줘야) 함수를 호출한 부분에서 그 값을 사용할 수 있습니다.
>>> def cal_upper(price):
increment = price * 0.3
upper_price = price + increment
return upper_price
>>> cal_upper(10000)
13000.0바인딩하면 다음과 같이 사용 가능합니다.
>>> upper_price = cal_upper(1000)
>>> print(upper_price)
1300.0
>>> upper_price = cal_upper(5000)
>>> print(upper_price)
6500.0
두개의 값도 반환할 수 있습니다. 예시로 상한가와 하한가를 반환하는 코드를 작성해보겠습니다.
>>> def cal_upper_lower(price):
offset = price * 0.3
upper = price + offset
lower = price - offset
return (upper, lower)
>>> (upper, lower) = cal_upper_lower(10000)
>>> upper
13000.0
>>> lower
7000.0- 모듈
다음 코드를 stock.py라는 이름의 모듈로 저장하여 사용하겠습니다.
def cal_upper(price):
increment = price * 0.3
upper_price = price + increment
return upper_price
def cal_lower(price):
decrement = price * 0.3
lower_price = price - decrement
return lower_price
author = "pystock"
파이썬 IDLE에서 stock 모듈을 임포트하고 함수를 호출하면 다음과 같은 결과를 얻을 수 있습니다.
>>> import stock
>>> print(stock.author)
pystock
>>> stock.cal_upper(10000)
13000.0
>>> stock.cal_lower(10000)
7000.0
모듈을 개발하고 이를 배포하고자 한다면 모듈에 구현된 함수가 정상적으로 동작하는지 충분히 테스트한 후 모듈을 배포해야 합니다. 이를 위해서는 모듈 파일 내에서 함수를 직접 호출하는 테스트 코드를 구현하는 것이 좋습니다.
def cal_upper(price):
increment = price * 0.3
upper_price = price + increment
return upper_price
def cal_lower(price):
decrement = price * 0.3
lower_price = price - decrement
return lower_price
author = "pystock"
if __name__ == "__main__":
print(cal_upper(10000))
print(cal_lower(10000))
print(__name__)
__name__이라는 변수는 파이썬 자체에서 사용하는 변수로서 특정 파이썬 파일이 직접 실행된 것인지 또는 다른 파이썬 파일에서 임포트된 것인지를 확인하는 용도로 사용됩니다. 특정 파이썬 파일이 독립적으로 실행됐다면 __name__이라는 변수는 __main__이라는 문자열을 바인딩하며 다른 파일에 임포트된 경우에는 자신의 파일명을 바인딩합니다. 위와 같은 코드로 작성하면 stock 모듈을 임포트해도 테스트 코드가 수행되지 않지만, stock.py를 직접 실행하면 테스트 코드가 출력됩니다.
알고리즘 트레이딩을 하려면 파이썬에서 시간을 잘 다룰 수 있어야 합니다. time 모듈을 사용해보겠습니다.
>>> import time
>>> time.ctime()
'Sun Oct 11 12:00:50 2015'
>>> cur_time = time.ctime()
>>> print(cur_time.split(' ')[-1])
2015
이번에는 time 모듈의 sleep 함수를 이용해 프로그램을 잠깐 잠재워 보겠습니다.
>>> for i in range(10):
print(i)
time.sleep(1)
os 모듈에 대해서도 간단하게 알아보겠습니다. 현재 경로를 구하려면 os 모듈의 getcwd 함수를 사용하면 되고, 특정 경로에 존재하는 파일과 디렉터리 목록을 구하려면 listdir 함수를 사용하면 됩니다.
>>> import os
>>> os.getcwd()
'C:\\Anaconda3\\Lib\\idlelib'
>>> os.listdir()
#현재 경로에 존재하는 파일과 디렉터리 목록이 리스트로 구성된 후 반환
다음과 같은 방법으로 해당 경로에는 28개의 파일 또는 디렉터리가 존재하는 것을 확인할 수 있습니다. 참고로 type 함수를 이용해 listdir 함수의 반환값 타입을 확인해보면 리스트임을 확인할 수 있습니다
>>> files = os.listdir('c:/Anaconda3')
>>> len(files)
28
>>> type(files)
<class ‘list’>- 파이썬 내장 함수
기본 내장 함수 중에 자주 사용되는 함수만 설명하겠습니다.
abs(x) 내장 함수는 정수형 또는 실수형 값을 입력받은 후 해당 값의 절댓값을 반환하는 함수입니다.
chr(i) 내장 함수는 유니코드 값을 입력받은 후 그 값에 해당하는 문자열을 반환합니다.
enumerate 내장 함수는 입력으로 시퀀스 자료형(리스트, 튜플, 문자열) 등을 입력받은 후 enumerate 객체를 반환합니다.
id(object) 내장 함수는 객체를 입력받아 해당 객체의 고윳값을 반환합니다.
len(s) 내장 함수는 리스트, 튜플, 문자열, 딕셔너리 등을 입력받아 해당 객체의 원소 개수를 반환합니다.
list 내장 함수는 문자열이나 튜플을 입력받은 후 리스트 객체로 만들고 해당 리스트를 반환합니다.
max 내장 함수는 입력값 중 최댓값을 반환합니다. 반대로 min 내장 함수는 입력값 중 최솟값을 반환합니다.
sorted 내장 함수는 입력값을 정렬한 후 정렬된 결괏값을 ‘리스트’로 반환합니다.
int(x) 내장 함수는 문자열을 인자로 입력받아 해당 문자열을 정수형으로 변환한 후 반환합니다. 반대로 str(x) 내장 함수는 객체를 입력받아 문자열로 변환합니다.
▷ 파이썬 클래스 (TBA...)
- 클래스란?
클래스를 이용해 프로그래밍하면 데이터와 데이터를 조작하는 함수를 하나의 묶음으로 관리할 수 있으므로 복잡한 프로그램도 더욱 쉽게 작성할 수 있습니다. 간단한 예제를 통해 파이썬의 클래스에 대해 본격적으로 배워보겠습니다
여러분이 명함을 제작하는 스타트업을 창업했다고 생각해 봅시다. 입력받은 데이터를 사용해 실제로 고객의 명함을 출력하는 함수를 하나 만들어보겠습니다.
>>> def print_business_card(name, email, addr):
print("-------------------------")
print("Name: %s" % name)
print("E-mail: %s" % email)
print("Office Address: %s" % addr)
print("-------------------------")
작성한 함수가 잘 동작하는지 테스트하기 위해 다음과 같이 함수에 인자값을 넣어 함수를 호출해봅니다.
>>> name = "kimyuna"
>>> email = "yunakim@naver.com"
>>> addr = "seoul"
>>> print_business_card(name, email, addr)
-------------------------
Name: kimyuna
E-mail: yunakim@naver.com
Office Address: seoul
-------------------------
>>> name2 = "DusanBack"
>>> email2 = "dusan.back@naver.com"
>>> addr2 = "Kyunggi"
>>> print_business_card(name2, email2, addr2)
-------------------------
Name: DusanBack
E-mail: dusan.back@naver.com
Office Address: Kyunggi
-------------------------
이런 방법을 사용해도 아직은 회원이 두 명이라 걱정이 없습니다. 하지만, 앞으로 회원 수가 늘어나면 개인 정보를 어떤 방식으로 저장하는 것이 좋을까요?
명함 출력에 사용된 이름, 이메일, 주소 등을 효과적으로 관리하기 위해 보통 아래과 같이 각 데이터에 대해 별도의 리스트 자료구조를 사용합니다. 다음과 같은 자료구조에서 첫 번째 회원에 대한 개인 정보를 얻기 위해서는 name_list[0], email_list[0], address_list[0]과 같이 각 리스트별로 인덱싱을 수행해야 합니다. 참고로 그림과 같이 데이터와 데이터를 처리하는 함수가 분리돼 있고 함수를 순차적으로 호출함으로써 데이터를 조작하는 프로그래밍 방식을 절차지향 프로그래밍이라고 합니다.

절차지향 프로그래밍 방식과 달리 객체지향 프로그래밍은 객체를 정의하는 것에서 시작합니다. 앞서 예시로 사용한 명함 스타트업을 통해 객체지향 프로그래밍에서 말하는 객체라는 개념을 알아보겠습니다.
먼저 명함을 구성하는 데이터를 생각해보면 명함에는 이름, 이메일, 주소라는 값이 있습니다. 다음으로 명함과 관련된 함수를 생각해보면 기본 명함을 출력하는 함수와 고급 명함을 출력하는 함수가 있을 것 입니다. 객체지향 프로그래밍이란 다음과 같이 명함을 구성하는 데이터와 명함과 관련된 함수를 묶어서 명함이라는 새로운 객체(타입)를 만들고 이를 사용해 프로그래밍하는 방식을 의미합니다.

파이썬을 통해 명함이라는 객체를 만들어 두면 명함 객체가 정수, 실수, 문자열과 마찬가지로 하나의 타입으로 인식되기 때문에 그림과 같이 여러 명의 명함 정보도 쉽게 관리할 수 있습니다.

파이썬에서 함수를 사용하기 전에 먼저 함수를 정의한 것처럼 클래스 역시 사용하기 전에 먼저 정의해야 합니다. 파이썬 IDLE를 실행한 후 다음과 같이 코드를 입력해 보겠습니다.
>>> class BusinessCard:
pass
파이썬에서 함수를 정의할 때 def라는 키워드를 썼던 것처럼 파이썬에서 클래스를 정의하려면 class 라는 키워드를 사용합니다. 위 코드에서는 가장 간단한 형태의 클래스 정의를 보여주기 위해 변수나 함수를 넣지 않고 pass라는 키워드만 사용했습니다.
보통 클래스와 인스턴스를 붕어빵 틀과 붕어빵으로 비유합니다. 클래스를 정의하는 것은 붕어빵을 만들 때 사용하는 기본 틀을 제작하는 것에 해당하며, 붕어빵 틀에 반죽을 넣어서 만들어진 붕어빵이 인스턴스에 해당합니다.
파이썬에서 정의된 클래스를 이용해 인스턴스를 생성하려면 다음과 같이 클래스 이름 뒤에 ()를 넣으면 됩니다. 어떻게 보면 인스턴스를 생성하는 과정은 함수를 호출하는 것과 비슷해 보입니다. 다음 코드에서 첫 번째 문장이 실행되면 같이 'BusinessCard'라는 클래스의 인스턴스가 메모리의 0x0302ABB0 위치에 생성되고 card1이라는 변수가 이를 바인딩하게 됩니다.
>>> card1 = BusinessCard()
>>> card1
<__main__.BusinessCard object at 0x0302ABB0>
생성된 인스턴스의 타입을 살펴보면 조금 전에 정의했던 BusinessCard 클래스임을 확인할 수 있습니다. 앞서 설명해드린 것처럼 파이썬의 class 키워드를 사용하면 원하는 객체(타입)를 만들 수 있습니다.
>>> type(card1)
<class '__main__.BusinessCard'>
이번에는 BusinessCard 클래스에 사용자로부터 데이터를 입력받고 이를 저장하는 기능을 수행하는 함수를 추가해보겠습니다. 참고로 클래스 내부에 정의돼 있는 함수를 특별히 메서드(method)라고 합니다.
다음 코드는 BusinessCard 클래스에 set_info라는 메서드를 추가한 것입니다. 메서드를 정의할 때도 함수를 정의할 때와 마찬가지로 def 키워드를 사용합니다. set_info 메서드는 네 개의 인자를 받는데, 그중 name, email, addr은 사용자로부터 입력받은 데이터를 메서드로 전달할 때 사용하는 인자입니다. 그렇다면 메서드의 첫 번째 인자인 self는 무엇일까요? 파이썬 클래스에서 self의 의미를 정확히 이해하는 것이 중요하지만 아직 제대로 설명하기는 조금 이른 감이 있습니다. 일단 클래스 내부에 정의된 함수인 메서드의 첫 번째 인자는 반드시 self여야 한다고 외우길 바랍니다.
>>> class BusinessCard:
def set_info(self, name, email, addr):
self.name = name
self.email = email
self.addr = addr
위 코드에서 메서드 내부를 살펴보면 메서드 인자로 전달된 name, email, addr 값을 self.name, self. email, self.addr이라는 변수에 대입하는 것을 볼 수 있습니다. 앞서 여러 번 설명한 것처럼 파이썬에서 대입은 바인딩을 의미합니다. 따라서 set_info 메서드의 동작은 그림 6.5와 같이 메서드 인자인 name, email, addr이라는 변수가 가리키고 있던 값을 self.name, self.email, self.addr이 바인딩하는 것입니다.

BusinessCard 클래스를 새롭게 정의했으므로 새롭게 정의된 클래스로 인스턴스를 생성해 봅시다. 붕어빵에 비유해 보면 붕어빵을 굽는 틀을 새롭게 바꿨으므로 새로 붕어빵을 구워보는 것입니다.
>>> member1 = BusinessCard()
>>> member1
<__main__.BusinessCard object at 0x030248F0>
새롭게 정의된 BusinessCard 클래스는 set_info라는 메서드를 포함하고 있습니다. 따라서 member1 인스턴스는 set_info 메서드를 호출할 수 있습니다.
그림을 보면 member1이라는 클래스 인스턴스를 통해 set_info라는 메서드를 호출할 수 있음을 확인할 수 있습니다. 단, 메서드에 인자를 전달하기 위해 파이썬 IDLE에서 괄호를 입력하면 메서드의 인자가 네 개가 아니라 세 개로 표시됩니다. 앞서 set_info 메서드를 정의할 때는 self, name, email, addr의 네 개의 인자가 사용됐는데 메서드를 호출할 때는 왜 세 개만 사용될까요?
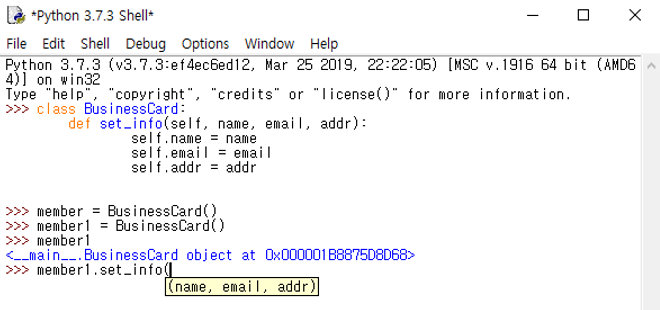
일단 다음 코드처럼 파이썬 IDLE가 알려주는 대로 세 개의 인자만 set_info 메서드의 입력으로 전달합니다. 항상 그렇듯이 파이썬 IDLE에서 에러가 발생하지 않았다면 정상적으로 코드가 실행된 것을 의미합니다.
>>> member1.set_info("Yuna Kim", "yunakim@naver.com", "Seoul")
self.name, self.email, self.addr과 같이 ‘self.변수명’과 같은 형태를 띠는 변수를 인스턴스 변수라고 합니다. 인스턴스 변수는 클래스 인스턴스 내부의 변수를 의미합니다. 위 코드에서 member1이라는 인스턴스를 생성한 후 set_info 메서드를 호출하면 메서드의 인자로 전달된 값을 인스턴스 내부 변수인 self.name, self.email, self.addr이 바인딩하는 것입니다. 클래스를 정의하는 순간에는 여러분이 생성할 인스턴스의 이름이 member1인지 모르기 때문에 self라는 단어를 대신 사용하는 것입니다.
정리해보면 set_info 메서드 내에서 self.name이라는 표현은 나중에 생성될 클래스 인스턴스 내의 name 변수를 의미합니다. 따라서 다음과 같이 인스턴스 이름을 적고 ‘.’를 붙인 후 인스턴스 변수의 이름을 지정하는 식으로 특정 인스턴스 변수에 접근할 수 있습니다.
>>> member1.name
'Yuna Kim'
>>> member1.email
'yunakim@naver.com'
>>> member1.addr
'Seoul'
이번에는 두 번째 회원에 대한 정보를 저장하는 인스턴스를 만들어보고, member2라는 이름을 통해 해당 인스턴스 내의 변수에 접근하겠습니다.
>>> member2 = BusinessCard()
>>> member2.set_info("Sarang Lee", "sarang.lee@naver.com", "Kyunggi")
>>> member2.name
'Sarang Lee'
>>> member2.email
'sarang.lee@naver.com'
>>> member2.addr
'Kyunggi'
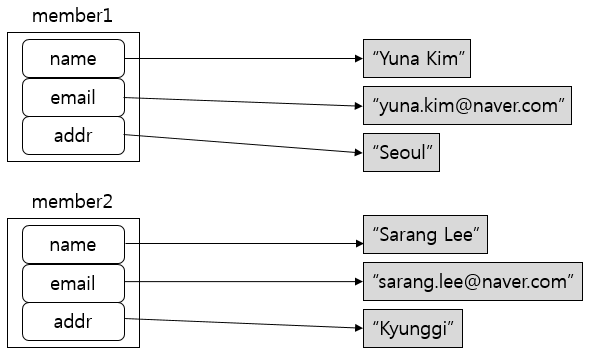
다음 그림은 클래스 인스턴스인 member1과 member2를 그림으로 표현해 본 것입니다. member1과 member2는 서로 동일한 이름의 인스턴스 변수인 name, email, addr을 갖고 있지만 각각 다른 데이터를 바인딩하고 있습니다.
이번에는 BusinessCard 클래스에 명함을 출력하는 메서드를 추가해보겠습니다.
>>> class BusinessCard:
def set_info(self, name, email, addr):
self.name = name
self.email = email
self.addr = addr
def print_info(self):
print("--------------------")
print("Name: ", self.name)
print("E-mail: ", self.email)
print("Address: ", self.addr)
print("--------------------")
BusinessCard 클래스를 재정의했으므로 다음과 같이 새로 인스턴스를 생성하고 메서드를 호출해보겠습니다.
>>> member1 = BusinessCard()
>>> member1.set_info("YunaKim", "yuna.kim@naver.com", "Seoul")
>>> member1.print_info()
--------------------
Name: YunaKim
E-mail: yuna.kim@naver.com
Address: Seoul
--------------------- 클래스 생성자
s
s
s
s
- self 이해하기
s
s
s
s
- 클래스 네임스페이스
s
s
s
s
- 클래스 변수와 인스턴스 변수
s
s
s
s
- 클래스 상속
s
s
s
s
▷ 파일 다루기
- 파일 읽기
s
s
s
s
- 파일 쓰기
s
s
s
s
'IT > Algorithm Trading' 카테고리의 다른 글
| 3) 키움증권 API 및 PyQt 기초 (0) | 2020.05.15 |
|---|---|
| 2) 실전 프로젝트 (PyCharm을 이용한 주소록 프로젝트) (0) | 2020.05.15 |
| Introduction of Algorithm Trading (알고리즘 트레이딩) (0) | 2020.04.17 |